
Deploying GPT-Neo’s 1.3 Billion Parameter Language Model Using AWS SageMaker
Language models are now capable of generating text that appears natural to humans. According to [Brown et al. 2020], humans only detect whether GPT-3 — one of the largest language models developed by OpenAI — generated short news articles accurately 52% of the time. Unfortunately, GPT-3 is not open-sourced (as of September 2021). EleutherAI has attempted to reproduce GPT-3 through GPT-Neo, a language model that has a similar architecture to GPT-3. At Georgian, we are very excited about the progress on large-scale language models and we compared GPT-3 and GPT-Neo in our previous blog post.
Many state-of-the-art NLP models are easily accessible through HuggingFace’s popular Transformers toolkit. Recently, HuggingFace and Amazon SageMaker reached a strategic partnership which, since GPT-Neo is available on HuggingFace, makes the deployment of GPT-Neo easier. In this blog post, we will walk through how we created a user interface for GPT-Neo 1.3B (containing 1.3 billion parameters) using Amazon SageMaker, and show how SageMaker’s auto-scaling helps us handle the dynamic traffic to our user interface.
You can see a demo of our user interface in the video above. Our user interface looks similar to the one that kiel.ai built. This is because we both used streamlit, a very convenient open-source framework for displaying data on web applications. A key difference between our UI and kiel.ai’s UI is that they deployed GPT-Neo using Docker, whereas we used Amazon SageMaker, which allows us to scale the number of compute instances hosting the GPT-Neo model depending on the traffic.
Cami Williams has written an awesome tutorial on deploying PyTorch models using AWS SageMaker. We followed her tutorial when deploying GPT-Neo. We were a bit confused about her communication flow diagram 😅, so we will draw another one here for clarity 😁.
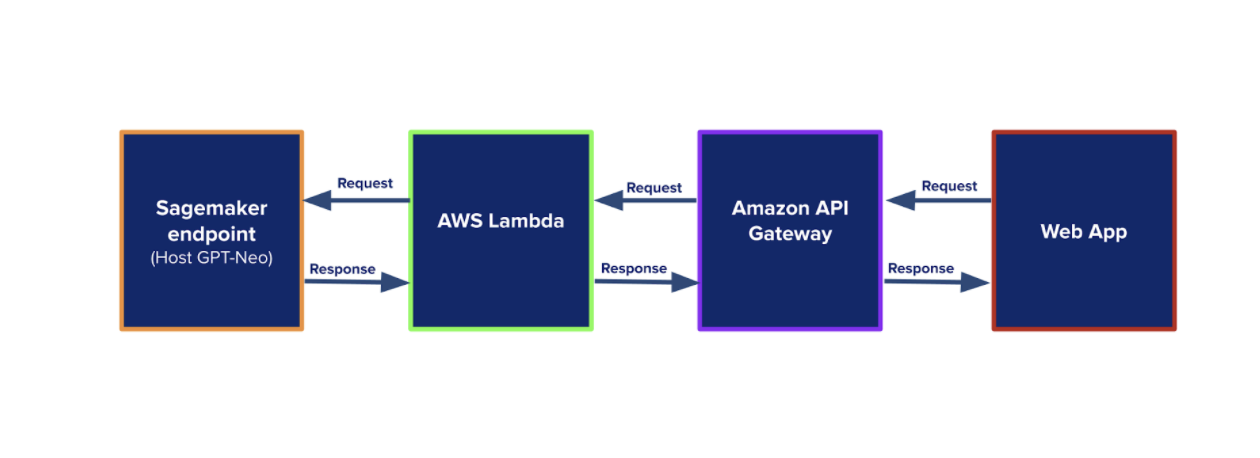
On the front end, the user types a prompt, then hits “Generate”. The web app sends a POST HTTP request to Amazon API Gateway. API Gateway calls AWS Lambda, which then invokes the SageMaker endpoint that’s hosting GPT-Neo. GPT-Neo generates text based on the prompt. The generated text travels back to the web app where it is displayed.
We followed Cami’s tutorial when setting up Lambda and API Gateway, so please refer to her tutorial for details on setting up those services. You can also find additional context about those services on the AWS machine learning blog. In the rest of this blog post, We will focus on the SageMaker side of the story and walk through how we created the model endpoint for GPT-Neo and automatically scale it using AWS Sagemaker.
Creating a SageMaker endpoint for GPT-Neo
We need to host our GPT-Neo model somewhere on the web so that it can take in the user’s input and generate some text. AWS SageMaker lets us do this through model endpoints. In the code below, we show how to create a model endpoint for GPT-Neo.
Note that the code above is different from the automatically generated code from HuggingFace. You can find their code by going here, then click Deploy -> Amazon SageMaker, and select AWS as the configuration. We tried their code and it did not work for us. The code above should work 😉, and you need to run it in a SageMaker notebook instance.
You may have noticed that we deployed the GPT-Neo model into a GPU instance, as we set instance_type=”ml.p3.2xlarge”. This is important because it greatly speeds up the inference.
Automatically scaling GPT-Neo models
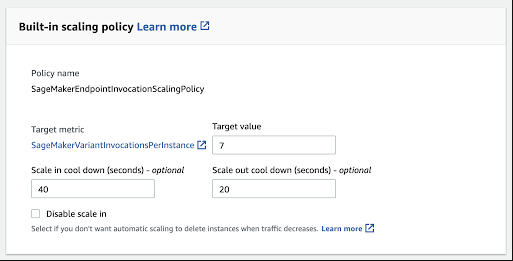
One of the advantages of deploying machine learning models using SageMaker is that it allows you to automatically scale the number of instances that host models. If there are suddenly lots of requests, one model will not be able to handle the traffic. By creating a scaling policy, SageMaker will scale out by spinning up more instances to host more models when traffic is high and will scale in by terminating some instances when traffic is low.
Note that the code above is different from the automatically generated code from HuggingFace. You can find their code by going here, then click Deploy -> Amazon SageMaker, and select AWS as the configuration. We tried their code and it did not work for us. The code above should work 😉, and you need to run it in a SageMaker notebook instance.
You may have noticed that we deployed the GPT-Neo model into a GPU instance, as we set instance_type=”ml.p3.2xlarge”. This is important because it greatly speeds up the inference.
Automatically scaling GPT-Neo models
One of the advantages of deploying machine learning models using SageMaker is that it allows you to automatically scale the number of instances that host models. If there are suddenly lots of requests, one model will not be able to handle the traffic. By creating a scaling policy, SageMaker will scale out by spinning up more instances to host more models when traffic is high and will scale in by terminating some instances when traffic is low.
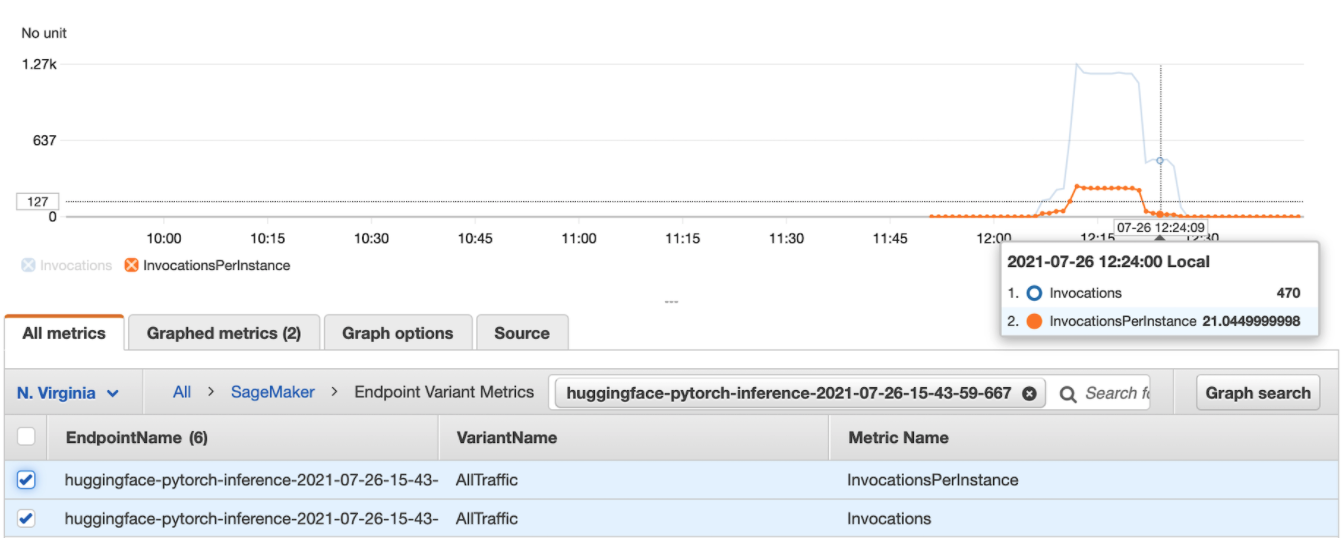
The figure above shows invocation statistics for this test. We started the test at 12:06, but interestingly, we don’t have additional instances ready until 12:22. This is because invocations divided by invocationsPerInstance is around five before 12:22, and this ratio is above 20 afterward. As a result, model latency started to decrease after 12:22, as shown in the figure below.
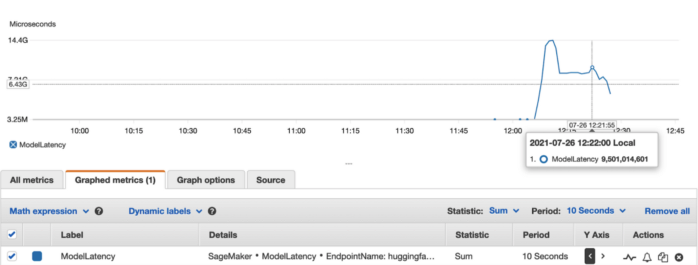
In the end, 15,800 requests were sent and 12,633 completed. The success rate is 79.9%. This experiment shows that instance creation takes time, and some requests will fail when instances are still being created. We tested again with more instances ready from the beginning — 40 instances initially auto-scaling to at most 50 instances at maximum. As expected, the success rate improved to 98.39%.
Wrapping up
Hopefully, this blog gives you everything you need to replicate our user interface for GPT-Neo, with a good understanding of the different services involved, and how to deploy GPT-Neo using Amazon SageMaker and automatically scale our application. As you can see, our user interface involves multiple open source projects: streamlit for the UI, the GPT-Neo model from EleutherAI, the wide availability of GPT-Neo on HuggingFace and Cami’s tutorial for setting up AWS services.
We hope this post is useful if you’re thinking about deploying GPT-Neo — this is our contribution back to the open-source community! 🙌
References
[Brown et al. 2020] Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei. Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
Read more like this
Introducing Georgian’s “Crawl, Walk, Run” Framework for Adopting Generative AI
Since its founding in 2008, Georgian has conducted diligence on hundreds of…
Practitioners Perspectives: GenAI Risks and Opportunities
Generative AI (GenAI) is creating new opportunities, and companies need to keep…
Georgian’s Top 5 Articles for 2021
Between continuously adapting to changing COVID-19 situations and hybrid work environments, 2021…